
这是一个创建于 382 天前的主题,其中的信息可能已经有所发展或是发生改变。
https://zhuanlan.zhihu.com/p/627566068
看了这篇文章,对 DDR 有两个疑问。求各位大佬不吝赐教。
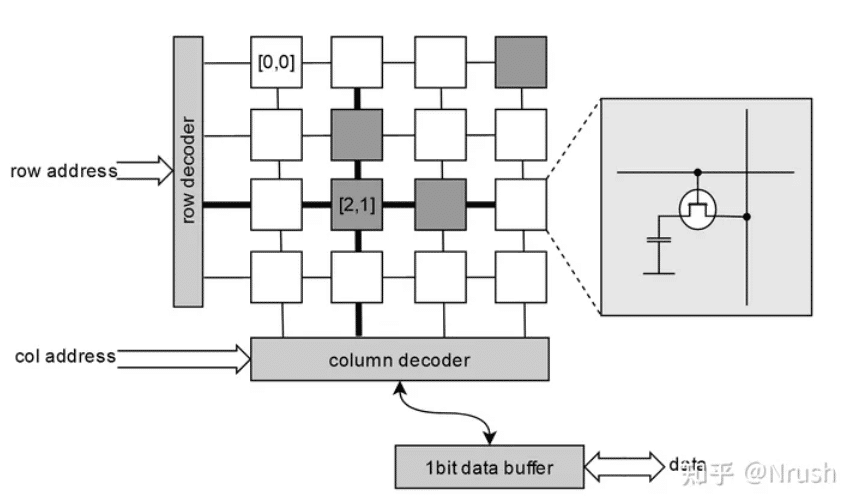 首先为什么说“column line 上的功能要远比 row line 上的器件复杂”,就因为 column 线连接着 data buffer 吗?还是说有着其他理由?
首先为什么说“column line 上的功能要远比 row line 上的器件复杂”,就因为 column 线连接着 data buffer 吗?还是说有着其他理由?
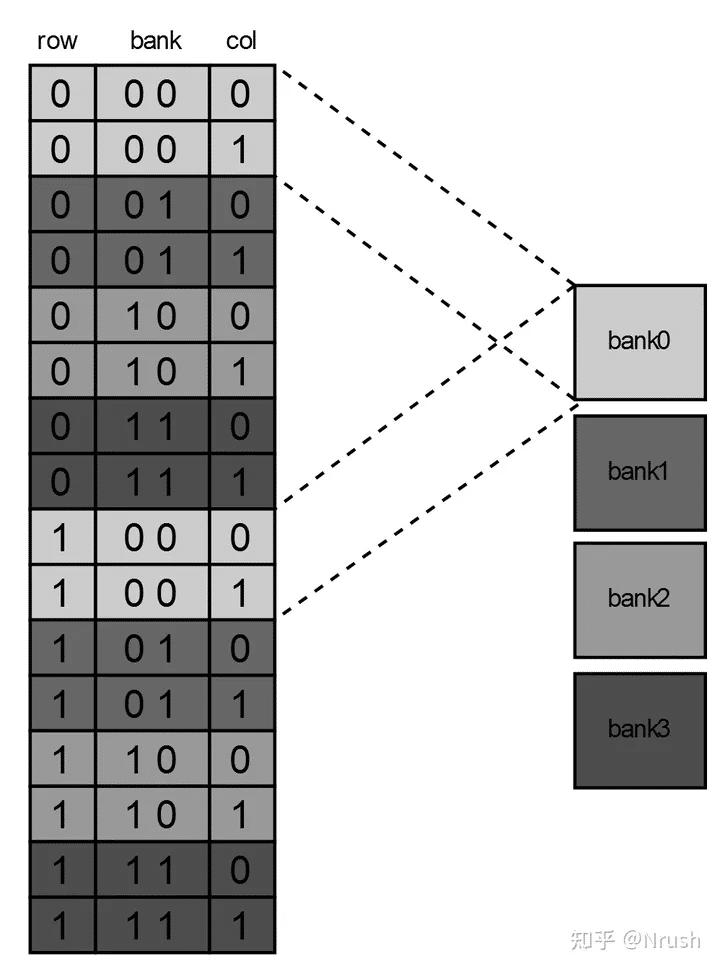
原文提到:多 bank 情况下,交叉读写不同 bank ,可以有效提高读写带宽。一个 bank 完成对一行的数据读写后,如果需要再次读取同一 bank 的另外一行上的数据,那必须耗费较长的时间重新打开一行,如果只有一个 bank ,那此时总线必须处于等待状态。这就叫做“交织”。
上面这一段话我理解它的意思,但是为什么上面这个图是这么画的? 但我觉得应该这样画吧:
- 0 0 0 0 [ bank0 ]
- 0 0 0 1 [ bank1 ]
- 0 0 1 0 [ bank2 ]
- 0 0 1 1 [ bank3 ]
- 以此类推...
这样我在对 地址 [ 0 0 0 0 ] 请求还没结束的时候,就可以去请求 [ 0 0 0 1 ] 地址了。或者说,这样的地址排布才是最“交织”的呀。( PS:原文说:该编码保证对同一 bank 的连续地址访问都是在同一行上的,我好像没有理解到 这个好处)
 |
1
liwufan 2023-10-02 18:38:29 +08:00 物理法则限制
1. column 上有放大器,电荷小导线长。 2. bank 切换不需要释放寄存器重新充电。 有个完美的视频讲解 分别在第 15 分钟和第 25 分钟有详细的讲解 |
 |
2
Ayahuasec 2023-10-02 18:39:57 +08:00 via Android DDR 控制器发出列地址以后,需要等待一段时间才能读写数据,在此期间可以多发几个地址,延迟时间到了以后连续读写。这样性能比较高。
DDR 跨行访问要先把当前行关掉,再打开新的行,这个步骤会引入额外的延迟。(或者考虑用自动预充电) 每个 Bank 是相对独立的,可以同时打开多个 Bank 的行。多个 Bank 只是共享了一个 DDR 的接口。 实际设计为了提高随机读写性能,我见过的比较多的设计是按 Row-Column-Bank 去编址的。 可以看一下 micron 的内存颗粒文档的时序图,我记得是比较全的。 |
 |
3
allmightbe OP @liwufan #1
@Ayahuasec #2 两位大佬,谢谢回答了。现在我对 DDR 又有了进一步的理解。但又有了新的疑问。 先说下我现有的理解: - x4/x8/x16 ,是指的 memory array 堆叠的高度。在一个 bank 里,原来一个坐标 [row ,col] 只能定位到 1bit ,现在如果是 x8 ,那么一个坐标 [row ,col] 可以定位到 8bit 。 - 2n/4n/8n prefetch ,主要指的 双边沿采样技术。如果是 x8 和 4n 预取的配置,那么一次访问,可以访问到 4*8bit ,也就是 4 字节。 对于上面的总结,我有点疑问,就是这个预取的东西,肯定是一个缓存,它是放到了什么位置呢,是 bank 内的一个缓存吗? 另外,这篇文章 https://depletionmode.com/ram-mapping.html 讲到了另外一个知识点: 'physical' address actual memory address 0x00f00010 -> 0x00f00010 0x00f00011 -> 0x00f00010 0x00f00012 -> 0x00f00010 0x00f00013 -> 0x00f00010 0x00f00014 -> 0x00f00010 0x00f00015 -> 0x00f00010 0x00f00016 -> 0x00f00010 0x00f00017 -> 0x00f00010 大概意思就是,如果 cpu 发出一个地址,如果这个地址在 8 字节对齐范围内,那么其实都对于同一个地址去了。之所以是 8 ,是因为一个 rank 里面有 8 个 chip 。 进一步的,因为有 8 字节的数据,但实际上又只需要 1 字节的数据,所以还要通过原地址低 3bit 来选出那个字节。 然后,作者说,这个东西和 CPU 的 cache line 有关系。 对于上面的总结,我有点疑问,这个一次性取 8 字节的东西,是在哪个地方或者说哪个接口? 另外,我最大的疑问,我现在把这个一次性 取 8 字节的东西 和 prefetch 有点搞混了,但是它们俩 又好像有点相似之处?所以它们到底是不是同样的东西?还是说 这两个技术 是同时存在的吗,可以根据具体的配置,举一个具体的例子吗? |
|
4
liwufan 2023-10-03 12:22:28 +08:00
@allmightbe
x4/x8/x16 是宽度,画 pcb 时候看的。 prefetch 是 stack depth ,burst mode 在 mode register 里面 set 好以后,读写是两个 buster 。ddr5 能做 16n 。 过去寄存和缓存是外置的,比如 rdimm ,rbdimm 。现在都做到 die 上面了。 cpu 一次取几个 bit 就是 primary bus width = banks x bank width ,和 rank 无关。 rank 是 oem 定制容量用的,客户要多大容量就插几个 rank 。不影响电气特性(超频玩家不属于正常客户 详细建议搜 micron product datasheet 。 |
|
5
Ayahuasec 2023-10-03 22:12:42 +08:00
@allmightbe
关于缓存,我印象里每个 bank 是有一个 row buffer 的。 一次性取 8 个字节,大概是因为 DIMM 的位宽是 64 bits 的吧(带 ECC 是 72 bits ,不过有效数据还是 64 bits ),但是实际上 burst length 对于 DDR4 的情况是常用 8 (因为好像从 DDR3 开始 prefetch 一般都是做的 8n ),也就是说一次连续的读写会涉及到 64 bytes 。如果要在一次读写中只让部分数据有效,一个是会用到 Data Mask 引脚,把部分数据位掩码掉;另一个是 burst chop ,让 burst length 变为 4 。但是如果都是短字节的随机读写,就会让 DDR 接口上一次读写操作中有大部分数据是浪费的。所以 CPU 里要做 Cache ,在需要的时候按 Page 为单位和 RAM 做数据交换,从而把内部比较随机的 RAM 读写变成相对连续的 DDR 读写。 不过关于一次读写的数据长度这一点上,我理解这个还是要和具体的 DDR 控制器设计相关的,我见过的一个用到 DDR 的设计是一个 Memory Channel 只带 2 个颗粒,DQ 位宽 16 bits ,burst length 固定为 8 ,这样的话发出一个地址请求,就会读写 16 bytes 的数据,内存控制器的地址是按 0x10 对齐的,也就是地址的低 4 位只用于配合读写长度进行字节的提取,但是 DDR 控制器到内存颗粒上总是一次读写就是连续的 16 bytes 。 |
|
6
allmightbe OP |
|
7
allmightbe OP @liwufan #4
@Ayahuasec #5 这篇文章 https://depletionmode.com/ram-mapping.html 讲的东西我稍微总结一下: 一个内存条是一个 module ,一个 module 有两面,一面就是一个 rank 。 一个 rank 上面有 8 个 chip (也就是有 8 个 黑色长方形坨坨,人眼能看到的) 一个 chip 里面,有 4 个 bank 。 它就是强调,一个地址转到了 DDR 控制器这边以后,没有用地址的部分 bit 来定位到某个 chip 上去(相反,比如会用 部分 bit 来定位到某个 row ),相反,这个地址线 连接到所有的 chip 上面去了,那么也就是说,所有 chip 都会根据地址线的信息 来返回数据。 然后地址线发送了一个地址以后,这个地址送给了所有 chip (文中是 8 个 chip ),然后 8 个 chip 都返回了 data 。 所以,最后 DDR 就一次性 返回了 8 个字节。 根据大佬的回答,和我看网上的文章。它说的这个 技术,应该不是 prefetch ,因为 prefetch 是发生在 bank 内部的,而文章说的事情,是发生在 某个 rank 上的所有 chip 上的。 PS:不排除这个作者说的东西,是有问题的。因为别的文章没有提到过。 |
|
8
allmightbe OP |
|
9
liwufan 2023-10-04 16:04:10 +08:00
感觉数理逻辑绕进死胡同了。我给不出准确答案。
你可以回忆一下模电概念帮助消化,prefetch 的目标是降低每个指令 duty cycle 。虽然 duty cycle 降低以后,直觉上是用无状态的 rank 去真刀真枪拼并发。但是现实上不太会这么搞,比如 https://blog.cloudflare.com/ddr4-memory-organization-and-how-it-affects-memory-bandwidth/ 里面这个内存控制器性能差异也就 2-3%。反过来看控制器里腾点空间再加一个通道,直接带宽翻倍,容量其实也翻倍了。所以用 rank 拉带宽是理论上的一种构想。 还有一点,模电上 bit 不能转为信息意义上的 byte ,int 0x01 和 char 0x31 的对位是人为定义的一种信息。所以在不考虑数电逻辑概念下,单 DQ 还有一些信号处理上的逻辑电路。 https://media-www.micron.com/-/media/client/global/documents/products/technical-note/dram/tn4040_ddr4_point_to_point_design_guide.pdf?la=en&rev=d58bc222192d411aae066b2577a12677 当然这都是些 driver 相关的简单逻辑电路,实际不会影响内存访问优化逻辑或者人脑思考的对错。但是用文字沟通时会产生很多混淆的概念。 |
|
10
allmightbe OP |
|
11
allmightbe OP @liwufan
@Ayahuasec 不过,micron 的 block 图里面,有一个地方不是太懂了。 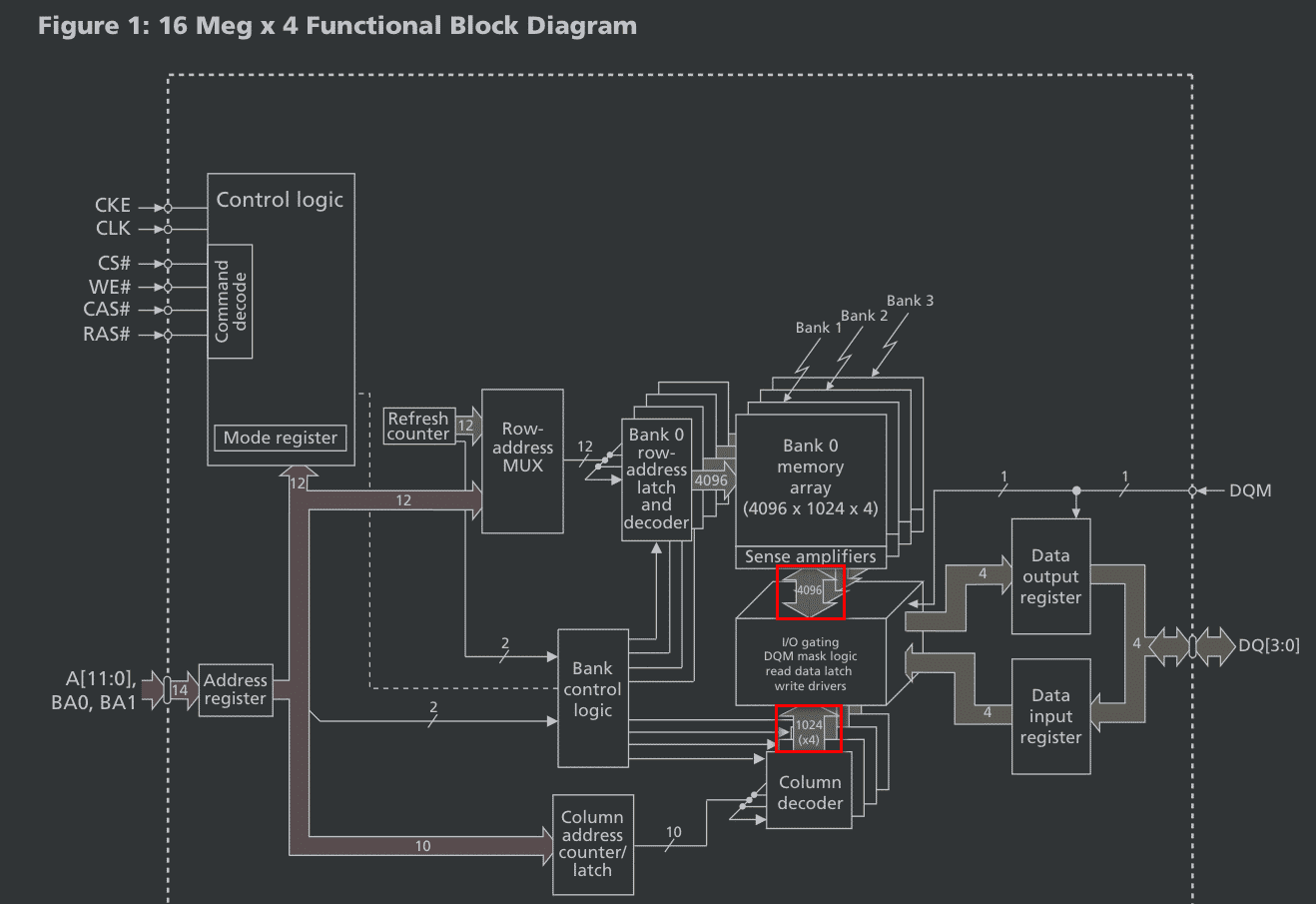 就是上图的两个粗箭头。 上面那个粗箭头,我是理解的:从 row line 选中一行后,就会输出 1024 x 4 的 data 出来,所以和这个粗箭头是 1024 x 4=4096 宽。 - 粗箭头,我理解是代表这个接口处的线很多。上面的粗箭头,则有 4096 根线。 但下面那个粗箭头,就不是很理解了: - 本身它是个粗箭头,我就不是很理解。这里,我理解是为了选择确认某一 col ,那也是 10 根线,就可以了。 - 另外,这个粗箭头,到底是 1024 的宽度,还是 1024x4 的宽度呢?(就是那个括号里的 x4 要算上吗) PS:不知道这个 block 图和实际硬件设计,是否能完全关联起来。也许这个粗箭头,只是一个逻辑上的概念。 |
|
12
allmightbe OP |
|
13
liwufan 2023-10-04 18:05:06 +08:00
1024 就是解码电路 https://en.wikipedia.org/wiki/Binary_decoder 。
我发的视频你没看,里面就是在讲电路 |
|
14
allmightbe OP @liwufan #13
是我蠢了。我理解这个 Decoder 的意思了。因为每行有 1024x4 的数据,所以下面那个粗箭头,需要有 4096 根来分别选中它们。 视频我又看了一遍,那我理解 下面那个粗箭头,应该就是 1024x4 的宽度(要把括号里的 x4 乘进去)。毕竟都叫 bit line 了。 视频我是看了,只是我是 最开始,当时那一遍没太看懂。后面这两天 又看了好多乱七八糟文档文章。 |
|
15
allmightbe OP  |
 |
16
deorth 2023-10-05 10:19:22 +08:00 via Android
v 站大佬真多啊
|
|
17
allmightbe OP @Ayahuasec #2
我见过的比较多的设计是按 Row-Column-Bank 去编址的。 ------- 对于这个地址交织,这个我是明确的:就是 row 必须在 col 左边。但至于 bank 到底放到哪里,这个有什么说法吗? https://imgur.com/bGKe6le.png 看了一个视频,里面是这么放的: - 因为访问一般是 4 字节对齐的,所以 col 的低 2bit 放最右边。 - 然后接着放 bank 的 2bit ,这样可以利用到 bank 之间的独立性 - 然后放 col 的高 1bit ,这样一轮循环后,使得 col 地址变成 1 时,就可以利用到 row hit 的高效率了。 不知道这么理解对不对。 |
|
18
allmightbe OP  |
|
19
Ayahuasec 2023-10-09 20:31:13 +08:00 via Android
@allmightbe #17 一个 column 对应的是多个 bits ,比如 x16 的颗粒是 16 bits ,如果一个控制器连的所有颗粒总计 DQ 是 64 位(比如一个 dimm ),就需要 4 个 x16 的颗粒,那这种情况下每个 column 地址其实是 8 bytes 。对应到按 1 byte 的字节的地址空间,其实是低 3 位不用。
举个例子,假如说地址空间是 32 位,那 Row-Column-Bank 编址可能是{row[15:0], column[9:0], bank_addr[2:0], 3'h0},这样连续读写可以用到所有 Bank 。 未对齐的访问一般在 Cache 端的控制器做,或者用 CPU 的异常中断做,Cache 到 DDR 一般只让对齐访问。 |
|
20
Ayahuasec 2023-10-09 20:42:10 +08:00 via Android
@allmightbe #18 修一个上一个回复(#19 )的 bug ,看到你这张图我想起来了,BL=8 的时候列地址的低 3 位也是不用的,保持为 0 。列地址一般是 10 bits ,上面这个例子其实应该是{row[15:0], column[9:3], bank_addr[2:0], 6'h0},或者也可以说是{row[15:0], column[9:3], bank_addr[2:0], column[2:0], 3'h0}。
|